
Today is Black Friday 2021. For those of you who are international, Black Friday is the day after Thanksgiving in America. It’s the BIGGEST commercial holiday we have. The rise of Amazon as the online retailer has forced brick and mortar stores to take more extreme measures to attract buyers. In the last few years we’ve seen more and more chaos surrounding Black Friday. We already know that news sources love spreading fear and chaos so we can guess at what they “think” about Black Friday. Let’s see how the general public feels via Twitter.
Grab Tweets about Black Friday
Instead of building a Web Scraper and potentially getting in trouble with Twitter, we’ll use the Twitter API. If you have a Twitter account, it’s really easy to get access to the Twitter API via the Twitter Developer Platform. Once you log in and follow the directions to keep copies of your keys and token somewhere safe, we can begin. I’ve opted to keep mine in a config.py file that I can import from.
There are many ways to use the Twitter API, but I’ve opted to use it the old-fashioned way – by sending requests. Before we begin our program, we’ll need to use pip to install the requests library. You can do that with the command below
pip install requestsBuilding A Twitter API Query
We’ll start off our program by handling our imports as we always do. For this program we’ll import the requests and json modules. We’ll be using requests to send our API requests and json to parse the response. I also imported the “Bearer Token” that we got earlier from the Twitter API here.
We’re going to use the recent searches endpoint of the Twitter API to grab only the recent tweets. Note that we’re not allowed to use the full search endpoint without research level access that has to be requested from the Twitter API and approved. The only header we need to send this endpoint is an Authorization header with the bearer token we got earlier.
Now let’s build a query. There are many ways to query for Black Friday news and you can feel free to build your query however you’d like. This example will build a query for Tweets containing the hashtag blackfriday. We will also filter our tweets to be English only, not have any links, and not be a retweet. Along with the query, we’ll also specify that we want 100 results back using the max_results key.
import requests
import json
from config import bearertoken
search_recent_endpoint = "https://api.twitter.com/2/tweets/search/recent"
headers = {
"Authorization": f"Bearer {bearertoken}"
}
params = {
"query": '#blackfriday lang:en -has:links -is:retweet',
'max_results': 100
}
Getting and Parsing a Response from Twitter
Now that we’ve built our request, let’s call the Twitter API for a response. Unlike the API request we sent in our example tutorial on what APIs are and how to use them, this is a GET request. GET requests do not have a body per se, but rather take parameters. After we get our response, we’ll simply use JSON to load up the response text and save it to a JSON file.
response = requests.get(url=search_recent_endpoint, headers=headers, params=params)
res = json.loads(response.text)
with open("bf.json", "w") as f:
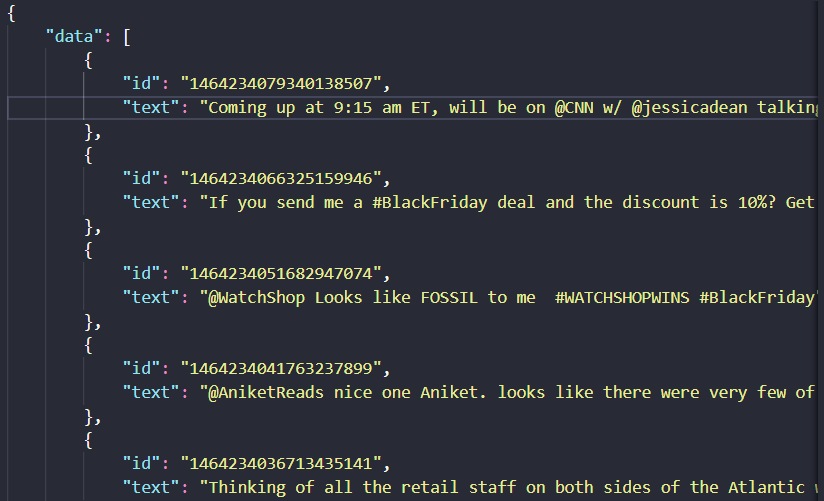
json.dump(res, f)Our JSON response should look like the image below.There are 100 total Tweets returned from the Twitter API. I’m only showing an image of the first few for us to get an idea of the data structure.
Some Requests Require an Upgraded Account
If you play around with your request, you may get an error like the one I got below when I tried to extract tweets just from the US. You’ll have to request access from Twitter. I have already requested access yet, I assume that I just haven’t been approved since it is the holidays. It actually says in the docs this should be usable for Sandbox accounts (the level of access I have at the time of writing) but I do not have access. I assume the documentation may not be fully up to date.
{
"errors": [
{
"parameters": {
"query": [
"#blackfriday lang:en place_country:us -is:retweet"
]
},
"message": "There were errors processing your request: Reference to invalid operator 'place_country'. Operator is not available in current product or product packaging. Please refer to complete available operator list at http://t.co/operators. (at position 22)"
}
],
"title": "Invalid Request",
"detail": "One or more parameters to your request was invalid.",
"type": "https://api.twitter.com/2/problems/invalid-request"
}
Use Natural Language Processing to Detect Sentiment of Tweets
Now that we have some Tweets to analyze, let’s use Natural Language Processing to detect the overall sentiment of the Tweets. To do this, we’ll be using The Text API, the most comprehensive sentiment analysis API online, to detect Text Polarity. Start by going to The Text API to get your free API key to follow this part of the tutorial.
Setting up the Request
As always, we’ll get started with importing the required modules. Just like with the Twitter API, we’ll need to import requests, json, and an API key. This time we’ll need the API key from The Text API. Let’s start by declaring the URL we need to hit. This time we’ll be using the polarity_by_sentence URL. You can find a description of the endpoints with examples in The Text API documentation.
After setting up the URL, let’s set up the headers. The headers will tell the server that we’re sending JSON content and pass the API key. We also need to open up the Tweets we got earlier, parse them, and use them to make up the body of the POST request we’re sending.
import requests
import json
from config import text_apikey
polarity_by_sentence_url = "https://app.thetextapi.com/text/polarity_by_sentence"
headers = {
"Content-Type": "application/json",
"apikey": text_apikey
}
with open("bf.json", "r") as f:
entries = json.load(f)
text = ""
for entry in entries["data"]:
text += entry["text"] + " "
body = {
"text": text
}
Getting and Parsing the Response
Now that everything is set up, we simply use the requests module to send a POST request and parse the JSON response back. We’ll then add up all the polarities by sentence and divide by the total number of sentences to get an average polarity. The average polarity of these 100 tweets gives us a sample of how people on Twitter are feeling about Black Friday. We can’t just divide by 100 because there may be more than 100 sentences in the Tweets.
response = requests.post(url=polarity_by_sentence_url, headers=headers, json=body)
results = json.loads(response.text)["polarity by sentence"]
print(results)
avg_polarity = 0.0
count = 0
for res in results:
avg_polarity += res[0]
count += 1
avg_polarity = avg_polarity/count
print(avg_polarity)Once we do this, we should see an output like the image below.
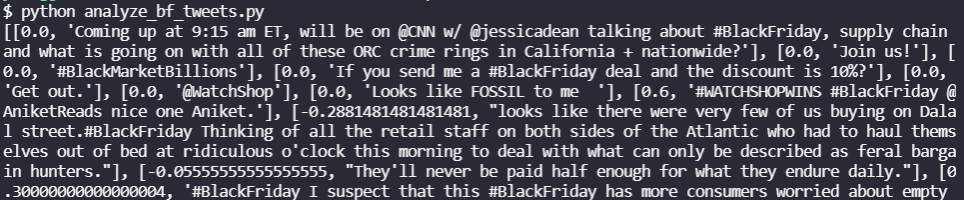
Our calculated polarity score for this set of 100 tweets is

This tells us that the average sentiment of the last 100 tweets about Black Friday on Twitter was slightly positive. You may get a different result depending on the timing of your analysis!
I run this site to help you and others like you find cool projects and practice software skills. If this is helpful for you and you enjoy your ad free site, please help fund this site by donating below! If you can’t donate right now, please think of us next time.

3 thoughts on “Black Friday: How Does Twitter Feel?”