

I recently had someone ask me what an encoder decoder model was and how an encoder decoder Long-Short Term Memory (LSTM) model is different from a regular (or stacked) LSTM. I’ve worked with many different kinds of RNNs, including LSTMs, and we’ve explored them on this blog. However, encoder decoder models are different from regular RNNs, they are set up so that part of the model “encodes” something and the next part of the model “decodes” it.
If you are simply trying to understand how these models work, I suggest just reading the conceptual parts. Feel free to read the technical portions for your own entertainment. They are mostly directed at aspiring machine learning engineers and people looking to build their own encoder decoder models.
While I was learning about encoder decoder models, I found myself asking three main types of questions. One, what does it do conceptually? Two, how can I make one, technically? And three, what makes these models special? In this article, we answer all of these questions. We cover:
- What is an Encoder Decoder Model?
- What does an Encoder Decoder do, conceptually?
- What does an Encoder Decoder do, technically?
- How are Encoder Decoder Models different from stacked RNNs?
- Why would you use an Encoder Decoder Model?
- Applications of Encoder Decoder Models
- How to make your own Encoder Decoder Model Interface
- The Encoder Class Interface
- The Decoder Class Interface
- The Encoder-Decoder Class Interface
- Summary of Encoder Decoder Models
What is an Encoder Decoder Model?
Encoder Decoder Models are a type of artificial neural network. They fall into the “deep” neural network category because they require multiple layers of neurons. They are also part of the seq2seq set of models because they take one sequence and transform it into another. Encoder Decoder Models came to mainstream machine learning attention for their use in language translation. We touch on this later in the applications section.
There are many types of encoding decoding structures for seq2seq models. The most popular of these is “attention”. Attention models became popular through the 2017 paper, Attention is All You Need. The decoder in an attention model maps different parts of the input selectively. This is a strong optimization for written text. Extensions of attention techniques include beam search, which uses a heuristic probabilistic search, and bucketing, which pads the sequences.
What does an Encoder Decoder do, conceptually?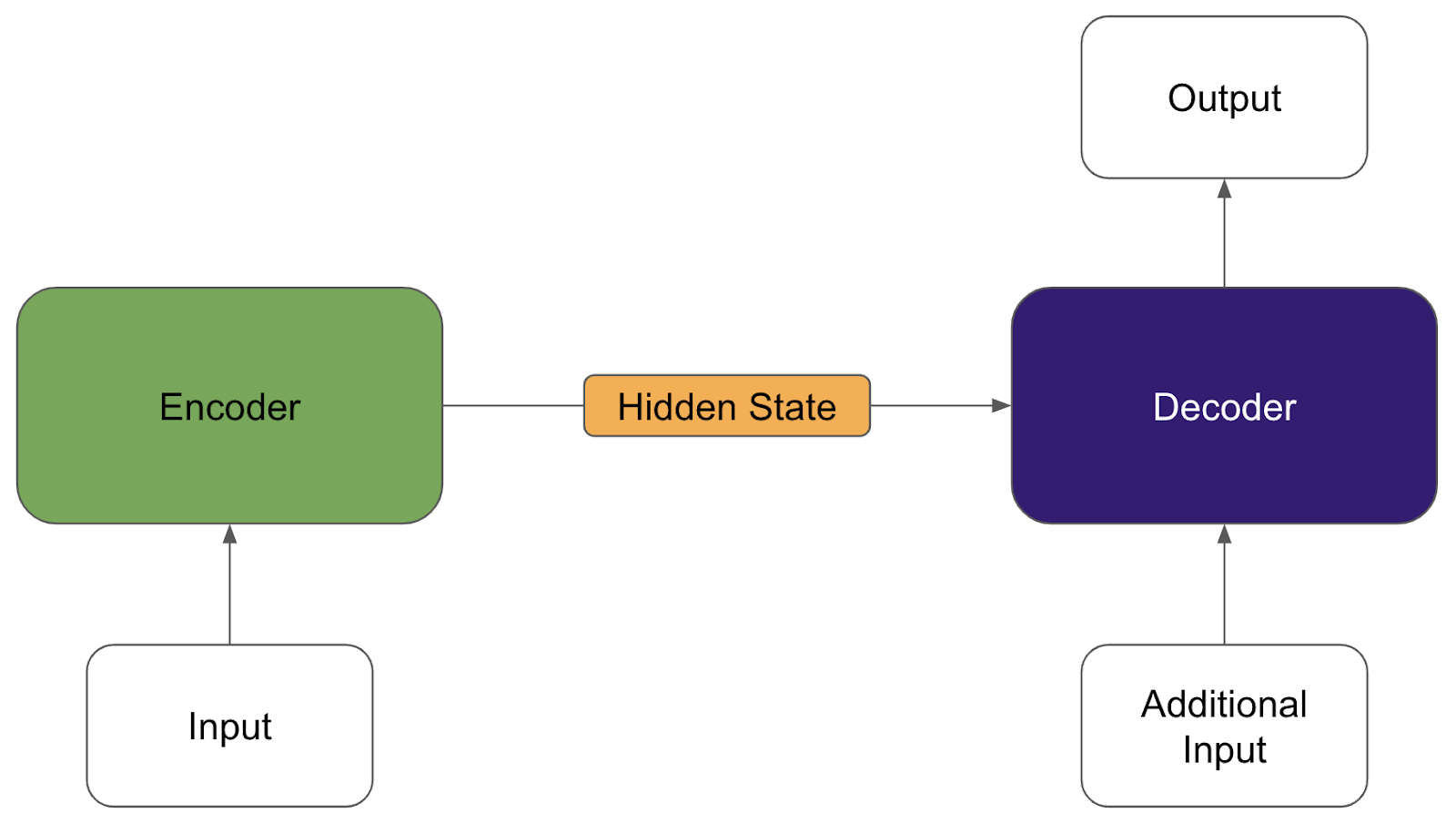

Conceptually, an encoder decoder model is quite simple. It consists of an encoder that turns the input into some encoded value, referred to as a “hidden state”, and a decoder that turns that hidden state into an output. Usually the decoder takes more inputs than just a hidden state. For example, when implementing an attention mechanism, the decoder also needs a matrix of alignment scores.
Let’s cover a more concrete example. Imagine that you need to translate between English and Pig Latin. Your input to the encoder may be “machine learning”. In this case, your desired output is “achine-may earning-lay”. Your encoder would encode the words “machine learning” into a hidden state of “m + achine” for “machine” and “l + earning” for “learning”. Then, your decoder would take the input of “m achine l earning” and apply the rules of Pig Latin to get your desired output, “achine-may earning-lay”.


Note that this is a contrived example intended to help you understand how an encoder-decoder model works conceptually. In reality, the hidden state would not be separated words, but a set of vectors (read: numbers). We are just using the words to indicate an example of how an input could be “encoded” and fed to the decoder to get an output. In the next section, we take a closer look at the technical details of how an encoder decoder works.
What does an Encoder Decoder do, technically?
Now that we have a conceptual understanding of encoder decoders, let’s take a deeper dive into the technical details. As we saw above, the encoder takes an input, such as “machine learning” and encodes it into a hidden state that it passes to the decoder. The conceptual example of the hidden state that we gave above was a representation of a middle step in the translation from English to Pig Latin. In reality, this hidden state is a matrix or vector.
Without an attention mechanism, which we represent above as the rules of Pig Latin but is really also a matrix, the encoder usually passes a vector, or a 1-dimensional matrix. However, this presents a challenge. Passing only a vector imposes a bottleneck on the size of the input. The longer the input, the more difficult it is to put all that information into one vector. Today, most encoder-decoder models use attention mechanisms as a way to get around this artificial limit.
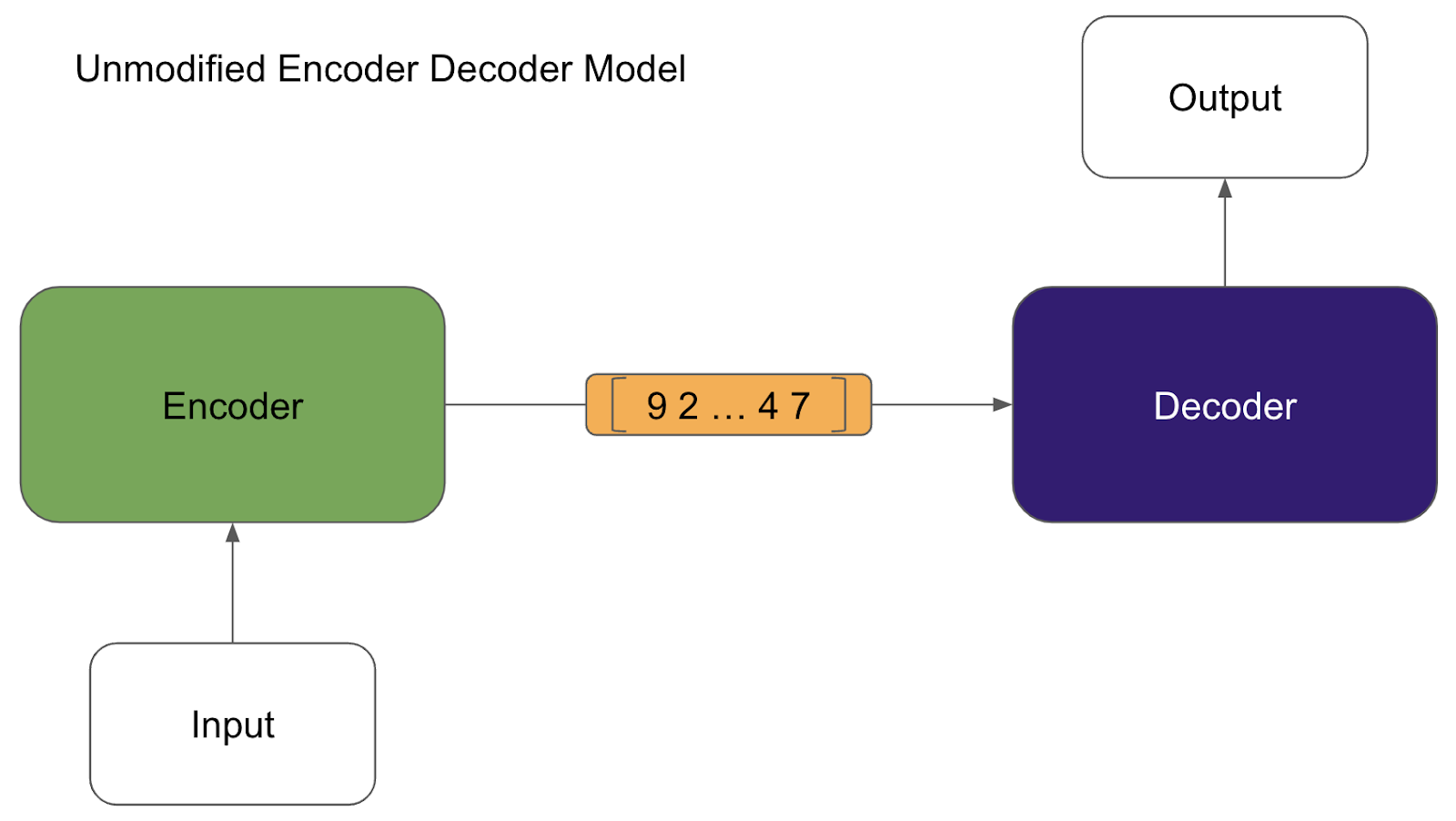
The image above shows a “traditional” or unmodified encoder decoder model. Assuming that there is no attention mechanism (read: no additional input), the encoder model passes a vector to the decoder model. The decoder model then uses this vector as its only input and produces an output.

The second image shows what an encoder decoder model that uses an attention mechanism could look like. In this case, the encoder could, and should, pass stacked vectors, which are interpreted as a matrix by the decoder. The decoder also takes an attention matrix as an input and combines the two inputs. There are many ways to combine these matrices, additively, multiplicatively, or any other way to mathematically manipulate two matrices together.
How are Encoder Decoder Models different from stacked RNNs?
Let’s loop back to the question that inspired this article. How are encoder decoder LSTMs (which are a form of RNNs) different from stacked LSTMs? The main difference is in how the information is passed between layers. In a traditional stacked RNN model, the layers pass information to each other without taking a step to combine all the information in one layer.
In an encoder-decoder model, all the information in the encoder is combined into one matrix at the last layer before being passed to the decoder. Another big difference is that encoder decoder models can work with sequences of different lengths. A stacked LSTM or RNN model produces output sequences of the same length as input sequences. Encoder decoder models do not require that.
Why would you use an Encoder Decoder Model?
The answer to this question is really quite simple. Encoder decoder models can provide better performance than a traditional stacked LSTM model. Another reason to use an encoder decoder model is that it can handle inputs and outputs of different lengths as mentioned above. In a general sense, encoder-decoder models are ideal for any machine learning task that requires context. Let’s look at some existing applications below.
Applications of Encoder Decoder Models
There are three main domains associated with the application of encoder decoder models. The most well known application is probably machine translation. Encoder decoder models are great for translating between languages. The input and output don’t have to be the same length, and applying attention allows the neural network to take the whole context of the sentence into account. This is especially important for cases where different parts of sentences are placed differently according to the language.
A second common application of encoder decoders is image captioning. Attention models are particularly useful in this case as illustrated in the paper Show, Attend, and Tell. Different attention models yield different outcomes as shown in the two images below (taken from the Show, Attend, and Tell paper). The “hard” attention model uses a stochastic approach and samples the image on each word generation. The “soft” attention model uses a deterministic approach by taking the expectation of the context vector.




The third domain that often applies encoder decoder models is sentiment analysis. Similar to the tasks above, sentiment analysis produces a different number of output tokens from the number of input tokens. Getting the sentiment of a sentence also requires context of the whole sentence. While it is possible to produce sentiment for each word, it’s not exactly useful for an overall sentence. For example, the sentence “that was super bad”, may produce an average sentiment when considering each word, but produces a low sentiment when considering the whole sentence with context.
How to make your own Encoder Decoder Model Interface


Creating an Encoder Decoder Model is quite a feat and we will leave covering creating an entire neural network to a future article. If you have a burning desire to code your own Encoder Decoder Model right now, check out the code from The Annotated Transformer. In this article, we are going to cover the interface for an Encoder Decoder Model to set you up to understand how you can create your own.
The example code that we look at below uses PyTorch and Python 3.9. To get started, you need to run `pip install pytorch` in your terminal. Then we need to import the Neural Network module from PyTorch with the line of code below.
import torch.nn as nnThe Encoder Class Interface
Our first order of business in creating an encoder decoder model interface is creating an Encoder class interface. Our encoder class extends the PyTorch neural network module. We need two functions in this interface. First, the classic `__init__` function; second a feed forward function.
The `__init__` function takes a set of keyword arguments and calls `super`, the `torch.nn.Module` init function with those arguments. We don’t implement our `forward` function here. We only define that it needs to take an input matrix, `X`. This function implements the logic for what the Encoder does with an input. For now, we will raise a `NotImplementedError` to let us know that the function has not been implemented yet.
class Encoder(nn.Module):
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
# X is the input matrix to the network
def forward(self, X):
raise NotImplementedErrorThe Decoder Class Interface
Next up is the Decoder class interface. Much like the Encoder interface, the Decoder interface extends the `nn.Module` object. The init function also works in the same way by calling `super` and passing the keyword arguments. Unlike the Encoder class, the Decoder interface has two functions to implement.
First, we need a function to get the hidden state. This function requires the output of the encoder function and optionally takes a list of arguments. The second function is a feed forward function again. This time, the feed forward function takes an input to the decoder and the state returned by the `init_state` function. Both of these functions will raise `NotImplementedError`s for now.
class Decoder(nn.Module):
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
# decoder needs encoder outputs and some args
# returns the state
def init_state(self, enc_outputs, *args):
raise NotImplementedError
# X is the input matrix for the decoder (eg pig latin rules)
def forward(self, X, state):
raise NotImplementedErrorThe Encoder-Decoder Class Interface
With both the Encoder and Decoder Class interfaces written, we move to writing the Encoder-Decoder Class Interface. The Encoder-Decoder Class Interface is set up much like the Encoder Class. It has two functions: `__init__` and `forward`. Its init function starts off much like the Encoder and Decoder Class init functions – by calling `super` and passing keyword arguments. After calling the `nn.Module` init function via `super`, it also stores the passed in encoder and decoder objects as attributes.
The feed forward function for the Encoder-Decoder Class Interface takes the two inputs for the encoder and decoder and an optional list of arguments. As we saw above, an Encoder Decoder Model gets a hidden state out of its encoder and passes that to the decoder. The feed forward function first gets the outputs of the encoder. Then, it translates those outputs into a state for the decoder using the decoder’s `init_state` function. Finally, it returns the decoded state for an output.
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)Summary of Encoder Decoder Models
In this article, we learned what Encoder Decoder Models are and how they work both conceptually and technically. We also explored how you can begin to implement your own version of an Encoder Decoder Model. Encoder Decoder models are neural networks that are split into two functional components. An encoder that turns a sequence into a state that includes all the context of the input, and a decoder that turns that state into an output.
Encoder Decoder Models rose to prominence propelled by attention mechanisms, which allow the decoder to focus on different parts of the input sequence. Another big advantage of Encoder Decoder models is that they can handle sequences of different lengths. This is a big improvement over a basic Seq2Seq model. The main uses of Encoder Decoder models include image captioning, sentiment analysis, and machine translation.
More by the Author
- Nested Lists in Python
- How to Automatically Transcribe an MP3 File in Notion
- Using AI to Analyze COVID Headlines Over Time
- Create a High Level Design Document (for Software Engineers)
- The Best Way to do Named Entity Recognition (NER)
I run this site to help you and others like you find cool projects and practice software skills. If this is helpful for you and you enjoy your ad free site, please help fund this site by donating below! If you can’t donate right now, please think of us next time.

