

We’re coming up on the second anniversary of the COVID-19 pandemic in America. There’s been a bunch of different variants, the CDC has shifted its stance at least 20 times, and the mask and vaccine protests rage on. Given all of this, I thought it would be interesting to analyze what the news has been saying about COVID over these last two years. In this post we will:
- Download News Headlines from 2020 and 2021
- Extract Headlines About COVID with AI
- Setup requests to extract COVID headlines
- Load and transform raw archived headline data from the NY Times
- Extraction of COVID headlines using AI
- Use AI to Get COVID Headlines Sentiments
- Setup asynchronous polarity value extraction
- Load up AI extracted COVID headlines to send to the API
- Asynchronously send requests to get sentiment values for headlines
- Plot COVID Headline Sentiments for 2020 and 2021 – see Sentiment Graphs Here
- A table of the number of COVID headlines per month
- Graphing sentiment polarity values for each headline
- Graphing monthly, yearly, and total sentiment values
- Avoiding an asynchronous looping RuntimeError
- The graph of average sentiment values of COVID per month since 2020
- Create a Word Cloud of COVID Headlines for 2020 and 2021 – see Word Clouds Here
- Moving the parse function to a common file
- Code to create a word cloud
- Loading the file and creating word clouds of COVID headlines
- Use NLP to Find the Most Common Phrases in COVID Headlines So Far
- Moving the base API endpoint and headers to a common file
- Setting up requests to get most common phrases
- Creating the requests to get most common phrases for each month
- Calling the most common phrases API
- The most common phrases in each month of COVID headlines
- Summary of using AI to analyze COVID headlines over time
To follow along all you need is to get two free API keys, one from the NY Times, and one from The Text API, and install the requests, aiohttp, and wordcloud libraries. To install the libraries, you can simple run the following code in your terminal or command line:
pip install requests wordcloud aiohttpDownload News Headlines from 2020 and 2021
The first thing we need to do is download our news headlines. This is why we need the NY Times API. We’re going to use the NY Times to download their archived headlines from 2020 to 2021. We won’t go through all the code to do that in this section, but you can follow the guide on How to Download Archived News Headlines to get all the headlines. You’ll need to download each month from 2020 to 2021 to follow this tutorial. If you want, you can also get the headlines for December 2019 when COVID initially broke out.
Extract Headlines about COVID with AI
After we have the downloaded news headlines we want to extract the ones that contain “COVID” in their title. We’re going to use The Text API to do this. The first thing we’ll need to do is set up our API requests and our map of month to month number as we did when we downloaded the headlines. Then we need to load and transform the JSON data into usable headline data. Finally, we’ll send our API requests and get all of the headlines from January 2020, through December 2021 that contain COVID in their headlines.
Setup Requests for COVID Headline Extraction with AI
Since we’re using a Web API to handle our extraction, the first thing we’ll need to do is set up sending API requests. We’ll start by importing the requests and json library. Then we’ll import the API key we got from The Text API earlier as well as the URL endpoint, “https://app.thetextapi.com/text/”. We need to set up the actual headers and the keyword endpoint URL. The headers will tell the server that we’re sending JSON content and pass the API key. Finally, we’ll set up a month dictionary so we can map month numbers to their names. This is for loading the JSON requests.
import requests
import json
from config import thetextapikey, text_url
headers = {
"Content-Type": "application/json",
"apikey": thetextapikey
}
keyword_url = text_url+"sentences_with_keywords"
month_dict = {
1: "January",
2: "February",
3: "March",
4: "April",
5: "May",
6: "June",
7: "July",
8: "August",
9: "September",
10: "October",
11: "November",
12: "December"
}
Load and Transform Raw Data into Headlines and Text
Now that we’ve set up our requests, let’s load up our headlines. We’ll create a simple load_headlines file with two parameters, year, and month. First, we’ll open up the file and headlines. Replace <path to folder> with the path to your folder. From here, we’re going to create an empty string and empty list so we can loop through each entry and append the main and print headlines that go with each entry.
In our loop, we’ll have to check the print_headline for each entry because sometimes it is empty. We will then check the last character of the print headline and turn it into a period if it’s punctuation. We’ll also check the last character of the main headline and get rid of it if it’s punctuation. We do this because we’re going to get all the sentences that contain the word COVID with our AI keyword extractor.
If the print headline exists, we’ll concatenate the main headline, a comma, and then the print headline and a space (for readability and separability) with the existing headlines text. If the print headline doesn’t exist, we’ll just concatenate the main headline. Else, if the length of the headlines text is greater than 3000, we’ll append the lowercase version to the headlines list and clear the string.
It doesn’t have to be 3000, choose this number based on your internet speed, the faster your internet, the higher number of characters you can send. We use these separate headlines to ensure the connection doesn’t timeout. At the end of the function, return the list of headlines strings.
# load headlines from a month
# lowercase all of them
# search for covid
def load_headlines(year, month):
filename = f"<path to folder>\\{year}\\{month_dict[month]}.json"
with open(filename, "r") as f:
entries = json.load(f)
hls = ""
hls_to_send = []
# organize entries
for entry in entries:
# check if there are two headlines
if entry['headline']["print_headline"]:
if entry['headline']["print_headline"][-1] == "!" or entry['headline']["print_headline"][-1] == "?" or entry['headline']["print_headline"][-1] == ".":
hl2 = entry['headline']["print_headline"]
else:
hl2 = entry['headline']["print_headline"] + "."
# append both headlines
if entry['headline']["main"][-1] == "!" or entry['headline']["main"][-1] == "?" or entry['headline']["main"][-1] == ".":
hl = entry['headline']["main"][:-1]
else:
hl = entry['headline']["main"]
hls += hl + ", " + hl2 + " "
elif entry['headline']['main']:
if entry['headline']["main"][-1] == "!" or entry['headline']["main"][-1] == "?" or entry['headline']["main"][-1] == ".":
hl = entry['headline']["main"]
else:
hl = entry['headline']["main"] + "."
hls += hl + " "
# if hls is over 3000, send for kws
if len(hls) > 3000:
hls_to_send.append(hls[:-1].lower())
hls = ""
return(hls_to_send)Extraction of COVID from Headlines using an NLP API
Now that we have the sets of headlines to send to the keyword extraction API, let’s send them off. We’ll create a function that takes two parameters, the year and month. The first thing the function does is call the load_headlines function we created earlier to load the headlines. Then we’ll create an empty list of headlines to hold the COVID headlines.
Next, we’ll loop through each set of headlines and create a body that contains the headlines as text and the list of keywords we want to extract. In this case, just “covid”. Then, we’ll send a POST request to the keyword extraction endpoint. When we get the response back, we’ll load it into a dictionary using the JSON library. After it’s loaded, we’ll add the list corresponding to “covid” to the COVID headlines list. You can see what an example response looks like on the documentation page.
Finally, after we’ve sent all the sets of headlines off and gotten the responses back, we’ll open up a text file. We’ll loop through every entry in the COVID headlines list and write it to the text file along with a new line character. You can also send these requests asynchronously like we’ll do in the section below. I leave that implementation as an exercise for the reader.
def execute(year, month):
hls = load_headlines(year, month)
covid_headlines = []
for hlset in hls:
body = {
"text": hlset,
"keywords": ["covid"]
}
response = requests.post(keyword_url, headers=headers, json=body)
_dict = json.loads(response.text)
covid_headlines += _dict["covid"]
with open(f"covid_headlines/{year}_{month}.txt", "w") as f:
for entry in covid_headlines:
f.write(entry + '\n')Use AI to Get COVID Headline Sentiments
Now that we’ve extracted the headlines about COVID using an AI Keyword Extractor via The Text API, we’ll get the sentiments of each headline. We’re going to do this by sending requests asynchronously for optimized speed.
Set Up Asynchronous Polarity Requests
As usual, the first thing we’re going to do is set up our program by importing the libraries we need. We’ll be using the json, asyncio, and aiohttp modules as well as The Text API API key. After our imports, we’ll create headers which will tell the server that we’re sending JSON data and pass it the API key. Then we’ll declare the URL that we’re sending our requests to, the text polarity API endpoint. Next, we’ll make two async/await functions that will handle the asynchronous calls and pool them.
The first of the async/await functions we’ll create will be the gather function. This function will take two parameters (although, you could also do this with one), one for the number of tasks, and the number of tasks. The asterisk in front of the tasks parameter just indicates a variable number. The first thing we’ll do in this function is create a Semaphore to handle the tasks. We’ll create an internal function that will use the created Semaphore object to asynchronously await a task. That’s basically it, at the end we’ll return all the gathered tasks.
The other function we’ll make will be a function to send an asynchronous POST request. This function will take four parameters, the URL or API endpoint, the connection session, the headers, and the body. All we’ll do is asynchronously wait for a POST call to the provided API endpoint with the headers and body using the passed in session object to complete. Then we’ll return the JSON version of that object.
import json
import asyncio
import aiohttp
from config import thetextapikey
headers = {
"Content-Type": "application/json",
"apikey": thetextapikey
}
text_url = "https://app.thetextapi.com/text/"
polarities_url = text_url + "text_polarity"
# configure async requests
# configure gathering of requests
async def gather_with_concurrency(n, *tasks):
semaphore = asyncio.Semaphore(n)
async def sem_task(task):
async with semaphore:
return await task
return await asyncio.gather(*(sem_task(task) for task in tasks))
# create async post function
async def post_async(url, session, headers, body):
async with session.post(url, headers=headers, json=body) as response:
text = await response.text()
return json.loads(text)Load Up AI Extracted COVID Related Headlines
Now that we’ve set up our asynchronous API calls, let’s retrieve the actual headlines. Earlier, we saved the headlines in text files. The first thing we’re going to do in this section is create a parse function that will take two parameters, a year and a month. We’ll start off the function by opening up the file and reading it into an “entries” variable. Finally, we’ll just return the entries variable.
def parse(year, month):
with open(f"covid_headlines/{year}_{month}.txt", "r") as f:
entries = f.read()
return entriesAsynchronously Send Requests to Extract Sentiment Values
With the headlines loaded and the asynchronous support functions set up, we’re reading to create the function to extract sentiment values from the COVID headlines. This function will take two parameters, the year and the month. The first thing we’ll do is load up the entries using the parse function created above. Then we’ll split each headline into its own entry in a list. Next, we’ll establish a connector object and a connection session.
Now, we’ll create the request bodies that go along with the headlines. We’ll create a request for each headline. We’ll also need an empty list to hold all the polarities as we get them. If we need to send more than 10 requests, we’ll have to split those requests up. This is so we don’t overwhelm the server with too many concurrent requests.
Once we have the requests properly set up, the only thing left to do is get the responses from the server. If there were more than 10 requests that were needed, we’ll await the responses and then add them to the empty polarities list, otherwise we’ll just set the list values to the responses. After asynchronously sending all the requests and awaiting all the responses, we’ll close the session to prevent any memory leakage. Finally, we’ll return the now filled up list of polarities.
# get the polarities asynchronously
async def get_hl_polarities(year, month):
entries = parse(year, month)
all_hl = entries.split("\n")
conn = aiohttp.TCPConnector(limit=None, ttl_dns_cache=300)
session = aiohttp.ClientSession(connector=conn)
bodies = [{
"text": hl
} for hl in all_hl]
# can't run too many requests concurrently, run 10 at a time
polarities = []
# break down the bodies into sets of 10
if len(bodies) > 10:
bodies_split = []
count = 0
split = []
for body in bodies:
if len(body["text"]) > 1:
split.append(body)
count += 1
if count > 9:
bodies_split.append(split)
count = 0
split = []
# make sure that the last few are tacked on
if len(split) > 0:
bodies_split.append(split)
count = 0
split = []
for splits in bodies_split:
polarities_split = await gather_with_concurrency(len(bodies), *[post_async(polarities_url, session, headers, body) for body in splits])
polarities += [polarity['text polarity'] for polarity in polarities_split]
else:
polarities = await gather_with_concurrency(len(bodies), *[post_async(polarities_url, session, headers, body) for body in bodies])
polarities = [polarity['text polarity'] for polarity in polarities]
await session.close()
return polaritiesPlot COVID Headline Sentiments for 2020 and 2021
Now that we have created functions that will get us the sentiment values for the COVID headlines from 2020 to 2021, it’s time to plot them. Plotting the sentiments over time will give us an idea of how the media has portrayed COVID over time. Whether they have been optimistic or pessimistic about the outcome, some idea of what’s going on at large, and whether or not the general sentiment is good. See all the graphs here
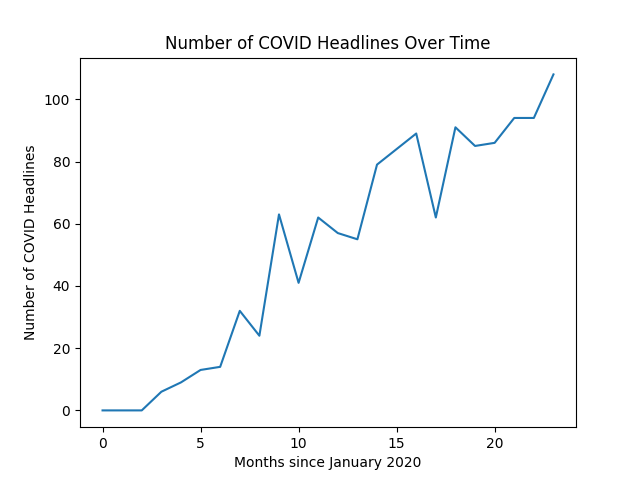
Number of COVID Headlines Over Time
First let’s take a look at the number of COVID headlines over time.
| Month | NYTimes Headlines About COVID |
| January 2020 | 0 |
| February 2020 | 0 |
| March 2020 | 0 |
| April 2020 | 6 |
| May 2020 | 9 |
| June 2020 | 13 |
| July 2020 | 14 |
| August 2020 | 32 |
| September 2020 | 24 |
| October 2020 | 63 |
| November 2020 | 41 |
| December 2020 | 62 |
| January 2021 | 57 |
| February 2021 | 55 |
| March 2021 | 79 |
| April 2021 | 84 |
| May 2021 | 89 |
| June 2021 | 62 |
| July 2021 | 91 |
| August 2021 | 85 |
| September 2021 | 86 |
| October 2021 | 94 |
| November 2021 | 94 |
| December 2021 | 108 |
Here’s the number of COVID headlines over time in graph format:

Graph Sentiment Polarity Values for Each Article
Now we’ve got everything set up, let’s plot the polarity values for each article. We’ll create a function which takes two parameters, the year and month. In our function, the first thing we’re going to do is run the asynchronous function to get the headline polarities for the year and month passed in. Note that this code is in the same file as the code in the section about using AI to get the sentiment of COVID headlines above.
Once we have the polarities back, we’ll plot it on a scatter plot using matplotlib. We’ll set up the title and labels so the plot looks good too. Then, we’ll save the plot and clear it. Finally, we’ll print out that we’re done plotting the month and year and return the list of polarity values we got back from the asynchronous API call.
# graph polarities by article
def polarities_graphs(year, month):
polarities = asyncio.run(get_hl_polarities(year, month))
plt.scatter(range(len(polarities)), polarities)
plt.title(f"Polarity of COVID Article Headlines in {month_dict[month]}, {year}")
plt.xlabel("Article Number")
plt.ylabel("Polarity Score")
plt.savefig(f"polarity_graphs/{year}_{month}_polarity.png")
plt.clf()
print(f"{month} {year} done")
return polaritiesGraph Monthly, Yearly, and Total Sentiment Polarity Values
We don’t just want to graph the polarity values for each article though, we also want to graph the sentiment values from each month and year. We’ll create a function that takes no parameters but gets the polarity values for each month in both years. Note that for some odd reason, there were exactly 0 mentions of COVID in the NYTimes headlines from January to March of 2020. Why? I don’t know, maybe there were mentions of “coronavirus” instead, but that’s out of the scope of this post and I’ll leave that as an exercise to you, the reader, to figure out.
This function will loop through both 2020 and 2021 as well as each of the first 12 numbers, we’ll have to add 1 to the month number because Python is 0 indexed. Once we loop through the years, we can plot the average polarity for each month. Once we’ve plotted both years, we will plot all the months on the same graph to get a full look at the COVID pandemic. Make sure to clear the figure between each plot for clarity.
# graph polarities by month
def polarities_month_graphs():
total_polarities_over_time = []
for year in [2020, 2021]:
month_polarities = []
for month in range(12):
# skip over the first three months
if year == 2020 and month < 3:
month_polarities.append(0)
continue
polarities = polarities_graphs(year, month+1)
month_polarities.append(sum(polarities)/len(polarities))
total_polarities_over_time += month_polarities
plt.plot(range(len(month_polarities)), month_polarities)
plt.title(f"Polarity of COVID Article Headlines in {year}")
plt.xlabel("Month")
plt.ylabel("Polarity Score")
plt.savefig(f"polarity_graphs/{year}_polarity.png")
plt.clf()
# get total graph for both years
plt.plot(range(len(month_polarities)), month_polarities)
plt.title(f"Polarity of COVID Article Headlines so far")
plt.xlabel("Months since March 2020")
plt.ylabel("Polarity Score")
plt.savefig(f"polarity_graphs/total_polarity.png")
plt.clf()Avoiding RuntimeError: Event Loop is closed
If you run the above code, you’re going to get a RuntimeError: Event loop is closed after running the asyncio loop. There is a fix to this though. This isn’t an actual error with the program, this is an error with the loop shutdown. You can fix this with the code below. For a full explanation of what the error is and what the code does, read this article on the RuntimeError: Event loop is closed Fix.
"""fix yelling at me error"""
from functools import wraps
from asyncio.proactor_events import _ProactorBasePipeTransport
def silence_event_loop_closed(func):
@wraps(func)
def wrapper(self, *args, **kwargs):
try:
return func(self, *args, **kwargs)
except RuntimeError as e:
if str(e) != 'Event loop is closed':
raise
return wrapper
_ProactorBasePipeTransport.__del__ = silence_event_loop_closed(_ProactorBasePipeTransport.__del__)
"""fix yelling at me error end"""Total Graph of average COVID Sentiment in NY Times Headlines from 2020 to 2021
Here’s the graph of the average COVID sentiment in NY Times Headlines from 2020 to 2021. Keep in mind that there were 0 headlines about COVID from January to March though, that’s why they’re at 0.


Create a Word Cloud of COVID Headlines for 2020 and 2021
Another way we can get insights into text is through word clouds. We don’t need AI to build word clouds, but we will use the AI extracted COVID headlines to build them. In this section we’re going to build word clouds for each month of COVID headlines since 2020. See all the word clouds here.
Moving the Parse Function to a Common File
One of the first things we’ll do is move the parse function we created earlier to a common file. We’re moving this to a common file because it’s being used by multiple modules and it’s best practice to not repeat code. We should now have a common.py file in the same folder as our polarity grapher file and word cloud creator file.
def parse(year, month):
with open(f"covid_headlines/{year}_{month}.txt", "r") as f:
entries = f.read()
return entries
Code to Create a Word Cloud, Modified for COVID
We’ll use almost the same code we used to create a word cloud for the AI extracted COVID headlines as we did for creating a word cloud out of Tweets. We’re going to make a slight modification here though. We’re going to add “covid” to the set of stop words. We already know that each of the headlines contains COVID so it doesn’t add any insight for us to see in a word cloud.
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# wordcloud function
def word_cloud(text, filename):
stopwords = set(STOPWORDS)
stopwords.add("covid")
frame_mask=np.array(Image.open("cloud_shape.png"))
wordcloud = WordCloud(max_words=50, mask=frame_mask, stopwords=stopwords, background_color="white").generate(text)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.savefig(f'{filename}.png')Load the File and Actually Create the Word Cloud from COVID Headlines
Now that we’ve created a word cloud function, let’s create the actual word cloud creation file. Notice that we’re importing the word cloud function here. I opted to create a second file for creating the COVID word clouds specifically, but you can also create these in the same file. This is just to follow orchestration pattern practices. In this file we’ll create a function that takes a year and a month, parses the COVID headlines from that month, and creates a word cloud with the text. Then we’ll loop through both 2020 and 2021 and each month that contains COVID headlines and create word clouds for each month.
from common import parse
from word_cloud import word_cloud
def make_word_cloud(year, month):
text = parse(year, month)
word_cloud(text, f"wordclouds/{year}_{month}.png")
for year in [2020, 2021]:
for month in range(12):
if year == 2020 and month < 3:
continue
make_word_cloud(year, month+1)Use NLP to Find Most Common Phrases in COVID Headlines
Finally, as an additional insight to how COVID has been portrayed in the media over time, let’s also get the most common phrases used in headlines about COVID over time. Like extracting the headlines and getting their polarity, we’ll also be using AI to do this. We’ll use the most_common_phrases endpoint of The Text API to do this.
Moving the Base API Endpoint and Headers to the Common File
The first thing we’ll do in this section is modify the common.py file we created and moved parse to earlier. This time we’ll also move the base URL and headers to the common file. We’ll be using the same base API URL and headers as we did for getting the sentiment values and extracting the keywords.
from config import thetextapikey
text_url = "https://app.thetextapi.com/text/"
headers = {
"Content-Type": "application/json",
"apikey": thetextapikey
}
Setup the Requests to Get Most Common Phrases using AI
The first thing we’ll do in this file is our imports (as always). We’ll be importing the json and requests libraries to send requests and parse them. We’ll also need the headers, base API URL, and parse function. Why are we using requests instead of asynchronous calls? We could use asynchronous calls here, but it’s not necessary. You can opt to use them for practice if you’d like. Finally, we’ll also set up the most_common_phrases API endpoint.
import json
import requests
from common import headers, text_url, parse
mcps_url = text_url + "most_common_phrases"
Creating a Monthly Request Function with an NLP API
Now that we’ve set up our requests for the most common phrases, let’s make a function that will get the most common phrases for a specific month. This function will take two parameters, a year and a month. The first thing we’ll do is create a body to send to the API. Then we’ll call the API by sending a POST request to the most common phrases endpoint. When we get our response back, we’ll load it into a JSON dictionary and extract out the list of most common phrases. Finally, we’ll write the most common phrases to an appropriate file.
# get the mcps asynchronously
def get_hl_mcps(year, month):
body = {
"text": parse(year, month)
}
response = requests.post(mcps_url, headers=headers, json=body)
_dict = json.loads(response.text)
mcps = _dict["most common phrases"]
with open(f"mcps/{year}_{month}_values.txt", "w") as f:
f.write("\n".join(mcps))
Call the API to Get the Most Common Phrases for Each Month
Now that we’ve written the function will extract the most common phrases from each set of monthly COVID headlines, we can just call it. We’ll loop through both years, 2020 and 2021, and all the months after March of 2020. For each loop, we’ll call the function we created above, and we will end up with a set of text files that contains the 3 most common phrases in headlines each month.
for year in [2020, 2021]:
for month in range(12):
if year == 2020 and month < 3:
continue
get_hl_mcps(year, month+1)Most Common Phrases in COVID Headlines for Each Month since 2020
These are the 3 most common phrases in COVID headlines that we got using AI. Each phrase is equivalent to a noun phrase.
| Month | 3 Most Common Phrases |
| April 2020 | possible covidcritical covid casesweary e.m.s. crews |
| May 2020 | covid syndromecovid patientsnew covid syndrome |
| June 2020 | covid infectionsmany covid patientscovid warning |
| July 2020 | fake covid certificatescovid spikelocal covid deaths |
| August 2020 | covid testscovid parentingcovid cases |
| September 2020 | covid riskcovid restrictionsd.i.y. covid vaccines |
| October 2020 | covid survivorcovid survivorscovid cases |
| November 2020 | covid overloadcovid testscovid laxity |
| December 2020 | covid pandemiccovid patientscovid breach |
| January 2021 | covid vaccinecovid survivorscovid spike |
| February 2021 | covid vaccineu.s. covid deathsrecord covid deaths |
| March 2021 | covid vaccinecovid vaccinescovid vaccine doses |
| April 2021 | effective covid vaccinescovid shotcovid certificates |
| May 2021 | covid vaccinecovid aidcovid data |
| June 2021 | covid vaccinessevere covidcovid cases |
| July 2021 | covid tollcovid returncovid patients |
| August 2021 | covid shotcovid shotscovid surge |
| September 2021 | covid vaccine boosterscovid vaccine pioneerscovid tests |
| October 2021 | covid vaccine mandatescovid boosterscovid pill |
| November 2021 | covid vaccine shotscovid vaccine mandatecovid vaccine mandates |
| December 2021 | covid pillcovid vaccinescovid boosters |
Summary of How to Use AI to Analyze COVID Headlines Since March 2020
In this post we learned how we can leverage AI to get insights into COVID headlines. First we learned how to use AI to extract headlines about COVID from the NY Times archived headlines. Then, we used AI to get sentiment values from those headlines and plot them. Next, we created word clouds from COVID headlines. Finally, we got the most common phrases from each set of monthly COVID headlines.
I run this site to help you and others like you find cool projects and practice software skills. If this is helpful for you and you enjoy your ad free site, please help fund this site by donating below! If you can’t donate right now, please think of us next time.

















{kind=link}
{kind=link}
{kind=link}