
Natural Language Processing (NLP) is the field of Artificial Intelligence/Machine Learning (AI/ML) that deals with how computers understand “natural languages”. In short, natural languages are those that arise from human interaction. Naturally, this means they are ever evolving, one of the many factors that makes this field challenging.
Other factors include that no known natural language can be defined with a set of rules, each language has its own grammatical structure, and each language sounds and looks different. Even though NLP is a complex field, you can easily get started in NLP by learning the concepts I outline in this post.
For a higher-level (less math heavy) overview check out this post on the basics of Natural Language Processing.
NLP Concepts: Multivariate Calculus and Linear Algebra
The math concepts you’ll have to know for NLP aren’t that different from the math concepts you’ll have to know for Machine Learning in general. The three main concepts are gradient descent, partial differentiation, and linear algebra. Each of these concepts really deserves its own class, but we’ll cover the basic ideas in this post.
Partial Differentiation
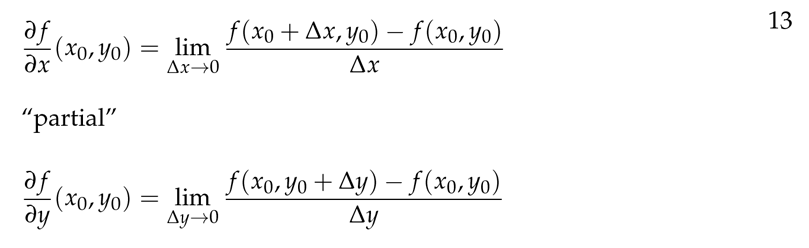
Partial differentiation is when we take the differential of a multivariate function in one direction. The image above shows how to take the partial derivatives of x and y in a function with two variables. As you can see, all we really do is assume that the other variable is a constant and take a regular derivative. To actually get a “value” of a partial derivative, we substitute the current value of the “constant” variable. The image below (also from MIT OCW) shows an example.
{kind=link}

Gradient Descent
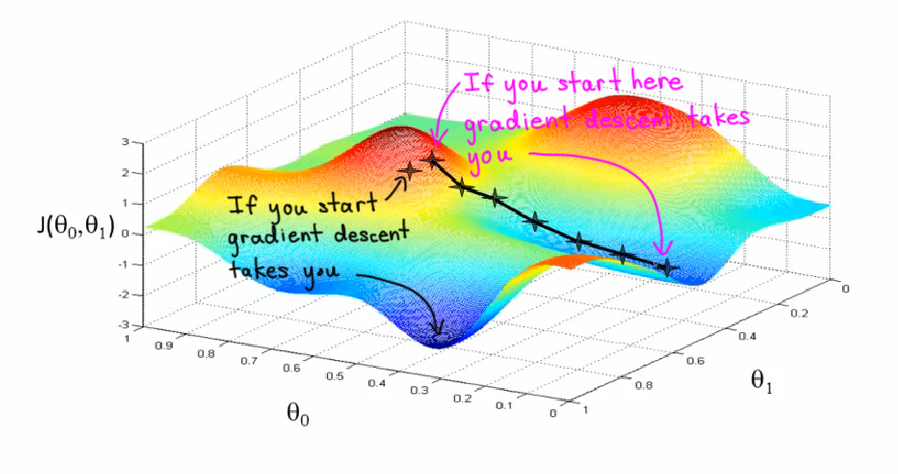
Gradient Descent is an iterative optimization algorithm. At each step of the algorithm we take a gradient of the function and step in the negative direction. The gradient is just the direction of the highest partial derivative. While gradient descent can be applied to the two dimensional example above for partial differentiation, it is most useful at three or higher dimensions. We simply use a three dimensional example for learning the concept. To picture gradient descent, think about the way water flows down a mountain. It follows the steepest routes, but it doesn’t always end up at the bottom of the mountain.
It’s important to understand that gradient descent can only lead us to a local minimum and does not guarantee finding the global minimum of a function. This is one of the reasons that Machine Learning models should be initialized at many different values to find the optimum descent. At higher dimensions, and especially as we have to do gradient descent more times, it becomes impractical. The calculations and training epochs just start taking too long. To overcome this problem we introduce stochastic and mini-batch gradient descent.
Stochastic Gradient Descent
In regular (also known as batch) gradient descent we update the model after we calculate the gradient using every instance of data we have. Stochastic Gradient Descent (SGD) basically says “hey, why not take an estimate with just one instance” and updates the model every instance. Clearly, this takes much less time when we have large amounts of data. SGD is able to find a local minimum much quicker than regular gradient descent and is also able to easily avoid shallow local minima. To picture Stochastic Gradient Descent, think of water rushing down a mountain after heavy rain. Sometimes the water overshoots and creates mini waterfalls along the way, but the water ends up at the bottom.
Mini-Batch Gradient Descent
Similar to SGD, mini-batch gradient descent is also a method to handle having too many data points to calculate. Instead of just using one point, mini-batch gradient descent uses a random “batch” of data points. It’s best to choose these batches randomly and independently each time. Unlike the stochastic method, it does not update the model for every instance, but rather in “mini-batches”. Mini-Batch Gradient Descent is able to avoid shallow local minima just like SGD, but is also more computationally efficient. You can think of Mini-Batch Gradient Descent like water rushing down a mountain after a medium rain. It doesn’t flood the river base, but the flow is strong enough to avoid the small lakes on the mountain. Mini-Batch Gradient Descent’s combination of robustness (avoiding local minima) and efficiency makes it the go-to gradient descent method.
Linear Algebra

{kind=link}
Yes, I know Linear Algebra is a senior level college math class. It’s way easier than it’s always made out to be though. We don’t even need to know everything like the inner workings of Gauss-Jordan Elimination, endomorphisms, or even eigenvectors and eigenvalues to get started. For introductory level Natural Language Processing, we only need to understand vector multiplication. At higher levels we’ll have to get into singular value decomposition, primal-dual formulations, kernel manipulations, and more.
For now, the main reason we introduce Linear Algebra is for vector manipulation. One hot encoding encodes words into vectors. This method of vector encoding words allows us to perform math on words. In NLP, this is what allows our neural networks to do calculations. This brings us perfectly into our next section on what we need to know about Neural Networks.
NLP Concepts: Neural Networks
As I mentioned in my high-level overview of Natural Language Processing, there are four main neural network architectures we should understand for NLP. To recap, these are Recurrent Neural Networks (RNN)s, Long Short Term Memory (LSTM), Connectionist Temporal Classification (CTC) loss, and Transformer models. CTC is technically not an entire architecture, but rather a way to calculate loss. For this post, we’re going to take a look at what a fully connected deep neural network (DNN) looks like and what a Recurrent Neural Network looks like.
Fully Connected Deep Neural Network
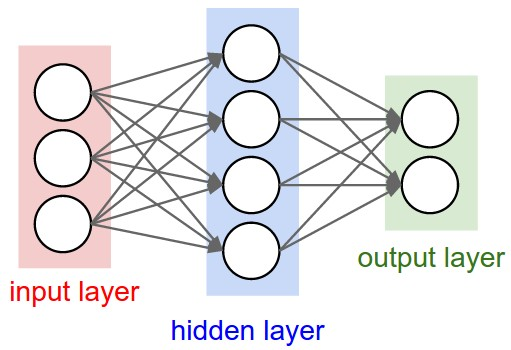
A fully connected neural network is a neural network that connects each node in a layer to each node in the next layer. Each node has a set of weights and biases that transform the value it sends to the next layer’s nodes. These weights and biases are usually passed through an activation function such as the sigmoid function we talked about in Logistic Regression to determine the output of the next node. Errors in the output are then passed back through the network to determine how to best update the weights and biases.
A deep neural network is just a neural network which has hidden layers. Hidden layers are layers between the input and output layer. For an example of how to build a fully connected deep neural network from scratch, check out this guide on how to build a neural network from scratch in Python.
Recurrent Neural Networks
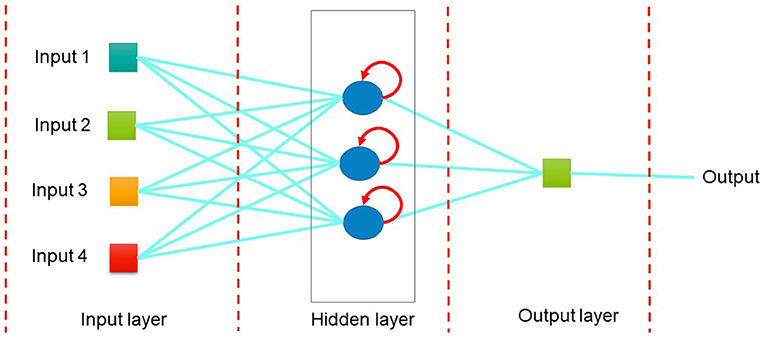
Recurrent Neural Networks get their name from the mechanic of nodes passing their output back to themselves. RNNs can be represented as graphs along a temporal sequence. They process sequences of inputs that rely on each other. That’s why they’re so useful for Natural Language Processing. In many natural languages, the words in a sentence aren’t that useful by themselves. Many times you need the entire sentence to make sense of it. Let’s take a look at what one of these “recurrent” nodes look like.

{kind=link}
The image above shows an unfolding of one node in a fully connected recurrent neural network. A fully connected RNN connects the output of each node to the input. Each node passes its output to both itself and the next layer as input. These “layers” of the node shown in the graph are actually steps in time. There are four types of RNNs: one-to-one, one-to-many, many-to-many, and many-to-one. These denote the way that the recurrence relation occurs. One-to-one connections direct the output of one node to one node. One-to-many connections directs the output of one node to many nodes. Many-to-one connections direct multiple nodes’ outputs to one node. Finally, many-to-many connections direct multiple nodes’ outputs to multiple nodes as input. Technically there are two types of many-to-many, the cases in which the second “many” is equal to the first and cases in which it is not.
NLP Concepts: Computational Linguistics
{kind=link}
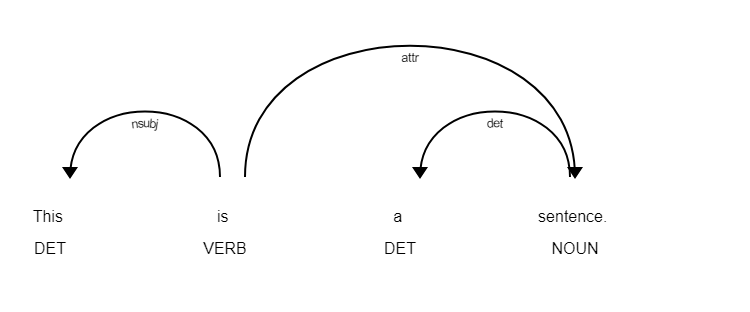
Finally, the last part of NLP that we’ll take a look at is Computational Linguistics. Computational Linguistics is in and of itself a complex interdisciplinary field consisting of pieces of linguistics, computer science, math, philosophy, and so many more fields. Computational Linguistics is the study of computational models of natural languages and appropriate computational approaches to linguistic questions. In terms of NLP, computational linguistics plays a big role in the way we approach modeling meanings of words, parts of speech, the polarity of a word or phrase, the overall topic of a text, named entity recognition, and more.
Computational Linguistics and Natural Language Processing have deeply intertwined histories. Both fields arose around the same time, the 1950s, to study the same thing: translation between Russian and English. Natural language processing is the study and practice of using computers to process, analyze, and contextualize large amounts of natural language data. Computational Linguistics focuses less on the computer science side and more on the mathematical modeling of natural languages.
I run this site to help you and others like you find cool projects and practice software skills. If this is helpful for you and you enjoy your ad free site, please help fund this site by donating below! If you can’t donate right now, please think of us next time.

3 thoughts on “Introduction to NLP: Core Concepts”